
توسعه سریعترین فناوری های ارتباطاتی در محاسبات با کارایی بالا (HPC)

کارشناسان حوزه فناوری، فناوریهای NVLink و NVSwitch که توسط شرکت انویدیا توسعه یافتهاند را بهعنوان راهکارهای پیشرفتهای برای افزایش سرعت و کارایی ارتباطات در سیستمهای HPC میشناسند و استنتاج مدلهای زبانی بزرگ (LLM) را با عملکرد فوق سریع تقویت میکنند. این فناوریها، با ارائه پهنای باند بالاتر و کاهش تأخیر، امکان پردازش سریعتر و کارآمدتر دادهها را فراهم میکنند. در ادامه، فناوریهای NVLink و NVSwitch و تأثیرات آنها در حوزههای مختلف بررسی و مقایسه میشوند.
معرفی فناوریهای NVLink و NVSwitch
فناوری NVLink؛ پلی بهسوی ارتباطات پرسرعت
در محاسبات پیشرفته، انتقال سریع و کارآمد دادهها بین واحدهای پردازش گرافیکی (GPU) و پردازندههای مرکزی (CPU) امری حیاتی است. فناوریهای سنتی مانند اسلات PCIe با محدودیتهایی در پهنای باند و تأخیر مواجه هستند که میتواند عملکرد سیستمهای HPC و هوشمصنوعی را محدود کند. برای رفع این چالشها، انویدیا فناوریهای NVLink و NVSwitch را معرفی کرده است.
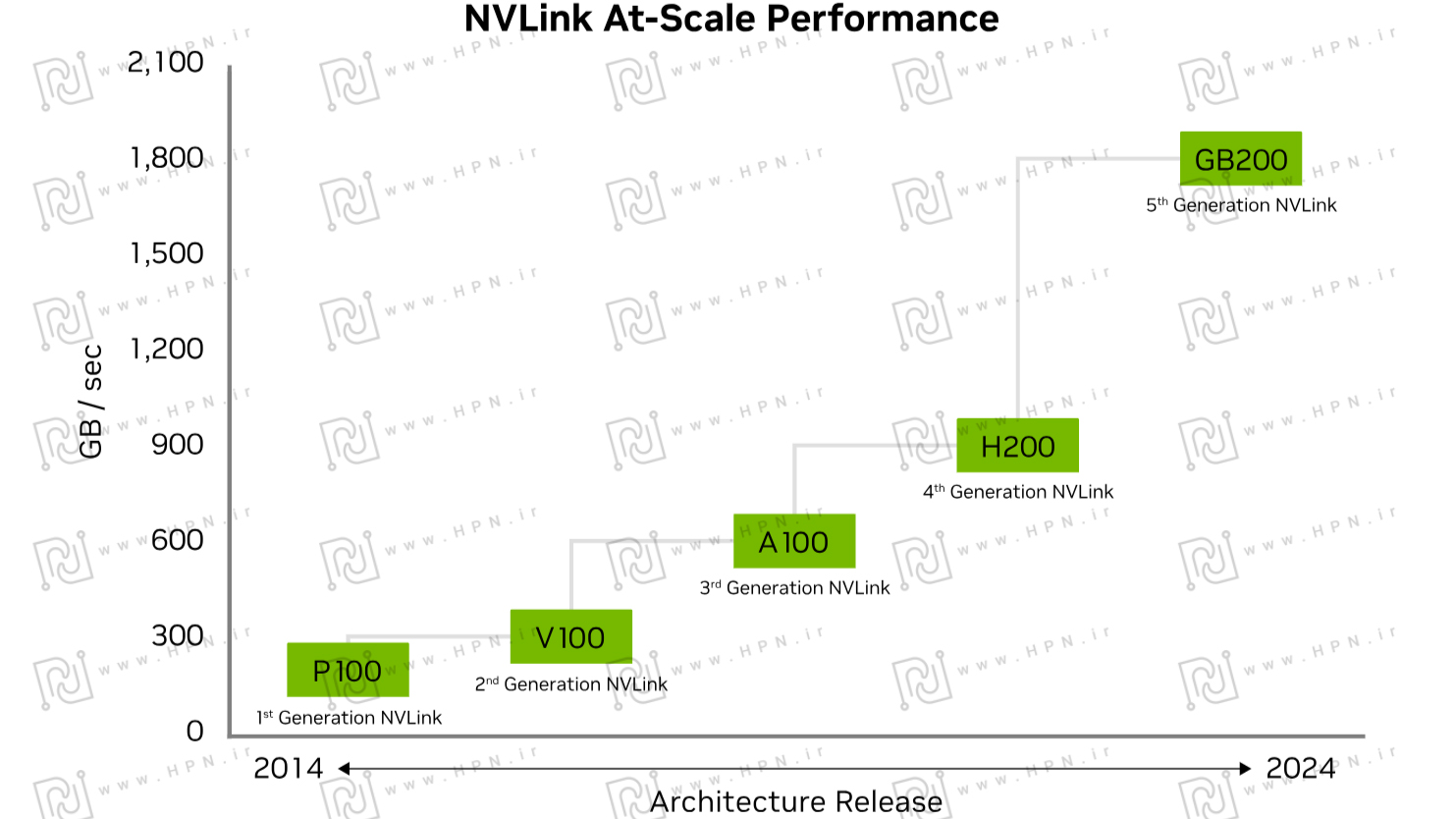
نمودار فوق روند پیشرفت فناوری NVLink را از نسل اول (ارائه شده در معماری Pascal) تا نسل پنجم (ارائه شده در معماری Blackwell) نشان میدهد. افزایش چشمگیر پهنای باند در هر نسل قابل مشاهده است؛ بهطوری که از چند صد گیگابایت بر ثانیه در نسل اول، به بیش از 2 TB/s در نسل جدید رسیده است. این پیشرفت مداوم، NVLink را به یکی از کلیدیترین فناوریهای ارتباطی در مراکز داده (Data Centers)، هوشمصنوعی(AI) و محاسبات با کارایی بالا(HPC) تبدیل کرده است.
فناوری SLI
از ابتدای توسعه کارتهای گرافیک، علاقهمندان به کامپیوتر همواره به دنبال روشهایی برای افزایش عملکرد سیستمهای خود بودهاند. حتی ایدهی غیرممکن اتصال مستقیم GPUها توسط مهندسان تحقیق و توسعه مطرح شد. انویدیا با توسعه فناوری SLI، نقطه عطفی در اتصال چندین GPU به یک سیستم واحد ایجاد کرد. فناوری SLI، انقلابی در اتصال چندین GPU به یک سیستم واحد ایجاد کرد. فناوری رابط اتصال مقیاسپذیر (SLI) که توسط انویدیا ارائه شد، امکان اتصال چندین GPU را فراهم کرد. با گذشت زمان، این فناوری با NVLink جایگزین شد که قدرت پردازشی بهروزتری ارائه میدهد. در این بخش، ما تفاوتهای اساسی میان این دو فناوری را بررسی میکنیم.
تفاوت های اساسی SLI در مقابل NVLink

اگرچه NVLink نسخه پیشرفتهای از SLI است، اما شباهتهای میان این دو محدود به اصل اتصال کارتها محدود میشود. هر دو توسط انویدیا توسعه یافتهاند، اما تفاوتهای متعددی دارند که آنها را منحصر به فرد میسازد.
توضیح تفاوتهای SLI و NVLink
- از آنجایی که SLI بر پیکربندی فرمانده-تابع (Master-Slave) تکیه دارد، این ساختار تنگناهای دادهای ایجاد میکند. اکنون فناوری NVLink با معماری موازی و شبکه توری، امکان انتقال داده بدون تنگنا را فراهم میکند. به همین دلیل، در SLI نقاط تنگنا در انتقال دادهها ایجاد میشود که در NVLink مشاهده نمیشود.
- پهنای باند هر دو فناوری نیز از یکدیگر متمایز است؛ NVLink تمامی GPUها را بهطور همزمان به کار میگیرد و برای هر واحد پهنای باندی بیش از 20 – 30 GB/s فراهم میکند.
ولی در فناوری SLI دادهها از واحد اصلی تقسیم شده است و به GPUهای تابع توزیع میشوند. به طوریکه سرعت انتقال داده حدود 2 – 3.5 GB/s (از طریق کانالهای دوگانه) تخمین زده میشود. - فناوری NVLink این امکان را فراهم میکند که حافظه کارتها بهصورت اشتراکی عمل کنند و ظرفیت کلی سیستم افزایش مییابد.
ولی در SLI، حافظه واحد اصلی محدودکننده ظرفیت سیستم است. - همچنین، حافظه GPUهای متصل در NVLink بهعنوان یک واحد یکپارچه عمل میکند؛ در حالی که در SLI، حتی پس از افزودن چندین GPU تابع، ظرفیت حافظه به همان میزان GPU اصلی باقی میماند. به همین دلیل، از نظر عملکردی NVLink جایگزین SLI شده است. اگرچه قیمتگذاری SLI رقابتی بود، اما بهعنوان یک فناوری قدیمی جذابیت کافی را ایجاد نمیکند؛ هرچند SLI همچنان از طریق یک رابط NVLink اصلاحشده با برخی از GPUهای انویدیا سازگار است.
- فناوری SLI تنها با کارتهای قدیمیتر انویدیا سازگار است، در حالی که NVLink برای کارتهای نسل جدید مانند (H200 و H100) طراحی شده است.
درنتیجه فناوری NVLink نسبت به نسل پیشین (SLI) عملکردی بینظیر و مقیاسپذیرتر ارائه میدهد.در ادامه به بررسی دقیق تر فناوری Nvidia NVLink میپردازیم.
فناوری NVLink؛ پلی بهسوی ارتباطات پرسرعت

فناوری NVLink یک پیوند ارتباطی با پهنای باند بالا است که توسط انویدیا برای افزایش سرعت تبادل داده بین GPUها، و هم سرعت تبادل داده بین GPU و CPU طراحی شده است. برخلاف اسلات PCIe که پهنای باند محدودی دارد، پل گرافیکی NVLink با ارائه پهنای باند بسیار بالاتر، ارتباط مستقیم بین پردازندههای گرافیکی را امکانپذیر میکند. نسخههای جدید پل های گرافیکی NVLink میتوانند تا 900 GB/s پهنای باند را فراهم کنند، که چندین برابر سریعتر از اسلات PCIe 5.0 است. این فناوری با کاهش تأخیر در پردازش دادهها، امکان اجرای مدلهای یادگیری عمیق را با کارایی بالاتر فراهم میآورد.
برای دریافت مشاوره تخصصی و انتخاب بهترین سخت افزار متناسب با نیازهای کسبوکار خود، با تیم مجرب HPN تماس بگیرید. تیم متخصص و مجرب HPN بهعنوان منبع معتبر در حوزه سختافزار و هوشمصنوعی آماده ارائه راهکارهای سفارشی و بهروز به شما است.
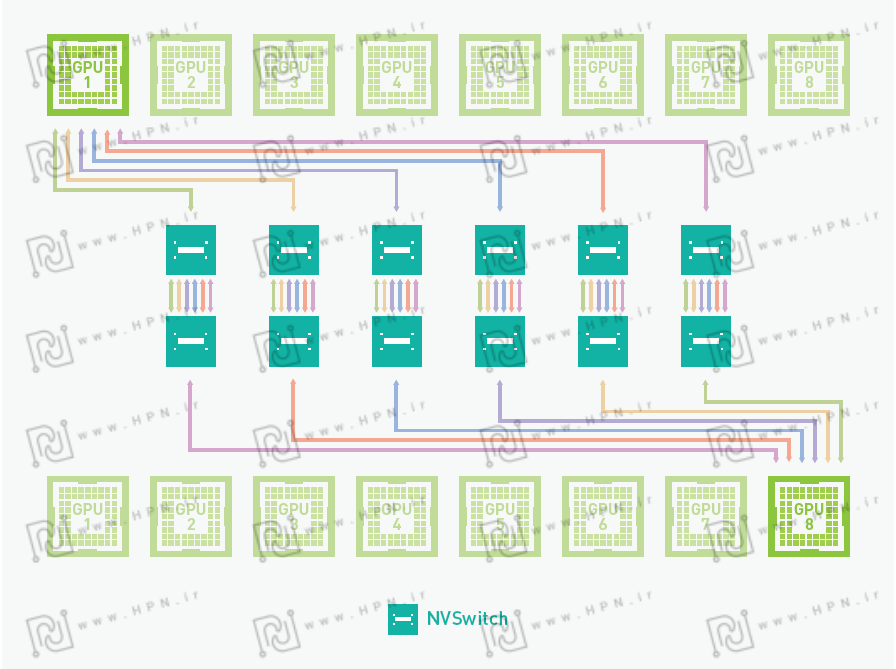
نمودار بالا معماری ارتباطی NVLink و اسلاتهایPCIe را در یک سیستم پردازشی مبتنی بر چندین GPU نشان میدهد. در این ساختار، پردازندههای گرافیکی (GPU) از طریق اتصال پرسرعت NVLink (مسیرهای سبزرنگ) به یکدیگر متصل شدهاند، درحالیکه ارتباط میان CPU، اسلاتهای PCIe و GPUها از طریق PCIe (مسیرهای بنفش) برقرار است. این طراحی، پهنای باند بالاتر و تأخیر کمتری را برای پردازشهای سنگین در حوزه هوش مصنوعی و محاسبات با کارایی بالا (HPC) فراهم میکند.
فناوری NVSwitch؛ گسترش مقیاس ارتباطات
فناوری NVSwitch در واقع یک تراشه (ASIC) است که به عنوان سوئیچ عمل میکند. به عبارت دیگر، این تراشه نقش یک سوئیچ با کارایی بالا را ایفا میکند که ارتباطات غیرمسدودکننده و با پهنای باند بالا را بین چندین GPU فراهم میسازد. این فناوری، اساس معماری NVLink را تکمیل میکند و امکان انتقال سریع دادهها در سیستمهای چند GPU مانند DGX-2 و HGX را فراهم میکند.
 پنل پشتی درقسمت عقبی DGX-2: اتصال بینابینی بردهای GPU از طریق فناوری NVLink
پنل پشتی درقسمت عقبی DGX-2: اتصال بینابینی بردهای GPU از طریق فناوری NVLink
فناوری NVSwitch یک سوئیچ ارتباطی پیشرفته است که متخصصان برای اتصال تعداد زیادی GPU در یک سیستم طراحی کردهاند. با استفاده از فناوری NVSwitch، کاربران میتوانند ارتباطی همزمان بین چندین GPU برقرار کنند. NVSwitch در مراکز داده و سرورهای پیشرفته مورداستفاده قرار میگیرد. پلتفرم HGX A100 از NVSwitch بهعنوان سوئیچ داخلی استفاده میکند تا اتصال بین کارتهای گرافیک را مدیریت کند. این فناوری به کاربران این امکان را میدهد که چندین GPU را بهصورت یکپارچه و با عملکرد بالا به یکدیگر متصل کنند، که موجب بهبود هماهنگی و افزایش سرعت پردازش دادهها میشود.
برای دریافت مشاوره تخصصی و انتخاب بهترین سخت افزار متناسب با نیازهای کسبوکار خود، با تیم مجرب HPN تماس بگیرید. تیم متخصص و مجرب HPN، بهعنوان منبعی معتبر در حوزه سختافزار و هوشمصنوعی، راهکارهای سفارشی و بهروز را مستقیماً به شما ارائه میدهد.
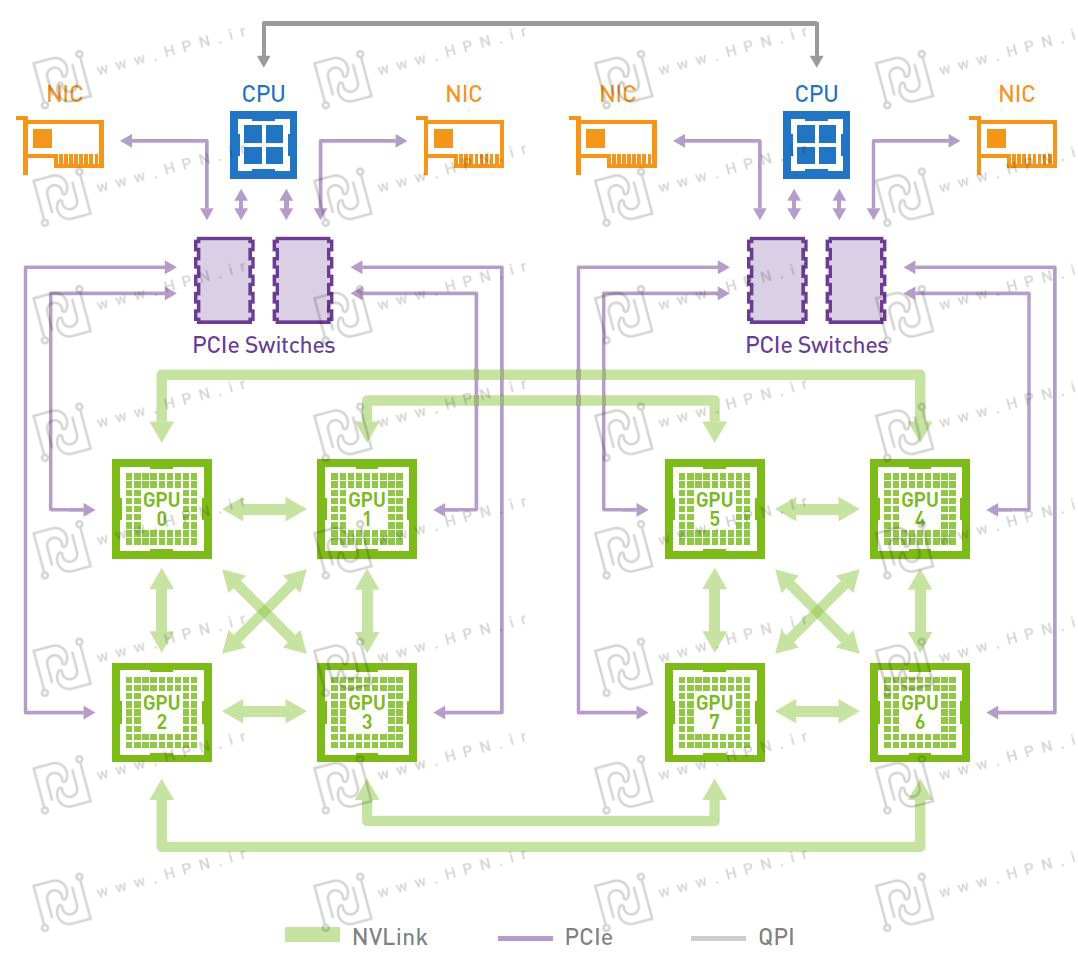 نمودار فوق اتصال دو GPU را نشان میدهد که این اتصالات می توانند میان همه GPUها باشند.
نمودار فوق اتصال دو GPU را نشان میدهد که این اتصالات می توانند میان همه GPUها باشند.
فناوری NVSwitch، امکان ایجاد یک سیستم کاملاً متصل بر پایه NVLink را برای 16 GPU فراهم میکند. بهطوری که هر GPU از اتصال قدرتمند 300 گیگابایت بر ثانیه بهرهمند است. این چارچوب ارتباطی، تنگناها و مراحل واسطهای را برطرف میکند و اجازه میدهد که تمامی 16، GPU بهصورت هماهنگ عمل کنند. در نتیجه، قدرت محاسباتی چشمگیر 2 petaFLOPS را در حوزه یادگیری عمیق آزاد میکنند و بستر مناسبی برای آموزش شبکههای پیشرفته هوش مصنوعی فراهم میآورند.
اما چه چیزی NVSwitch را از راهکارهای ارتباطی سنتی متمایز میکند؟
فناوریهای پیشرفته سختافزاری و نرمافزاری در کنار هم، NVSwitch را به راهکاری واقعاً شگفتانگیز تبدیل کردهاند. NVSwitch از انتقال دیجیتال پرسرعت، مکانیزمهای پیشرفته تشخیص و تصحیح خطا و الگوریتمهای مسیریابی هوشمند بهره میبرد تا حداکثر انتقال دادهها را تضمین و تأخیر را به حداقل برساند. استفاده از NVSwitch این امکان را فراهم کرده است که محاسباتی که پیشتر ساعتها طول میکشید، اکنون در چند دقیقه انجام شوند. این فناوری تغییردهنده بازی برای صنایعی است که به قدرت محاسباتی شدید متکی هستند، مانند تحقیقات علمی، تحلیل دادهها و یادگیری عمیق.
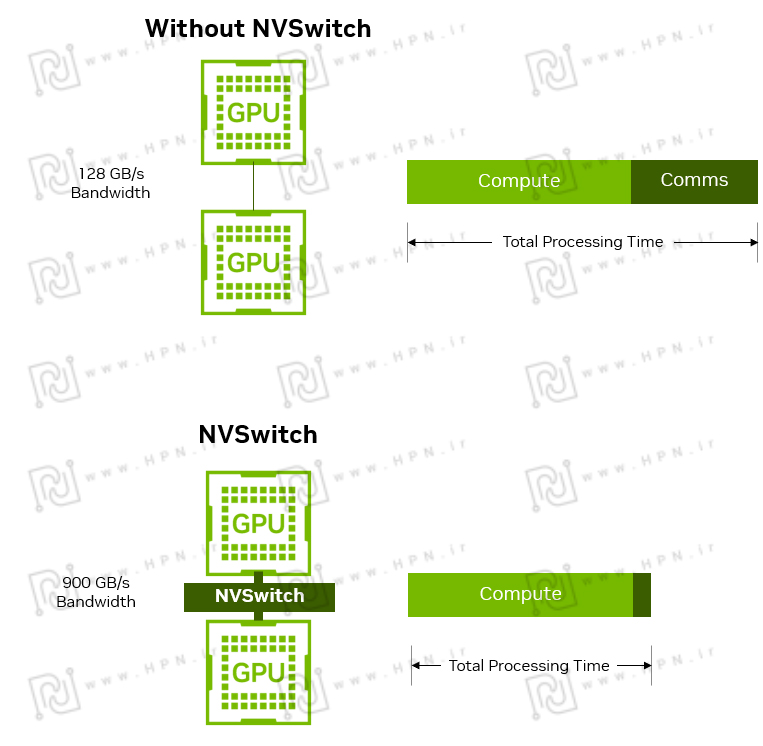 ارتباط چند-GPU با و بدون NVSwitch
ارتباط چند-GPU با و بدون NVSwitch
این سوئیچ در تسریع استنتاج مدلهای زبانی بزرگ (LLM) در ساختار چند GPU نقشی حیاتی ایفا میکند. برای دستیابی به مقیاسپذیری مطلوب در یک سرور هوشمصنوعی چندGPU، ابتدا باید از کارتهای گرافیکی با پهنای باند ارتباطی بالا بین GPUها استفاده شود. همچنین، فراهمکردن اتصال سریع برای تبادل داده میان تمام GPUها ضروری است تا بتوانند در کوتاهترین زمان ممکن اطلاعات را ردوبدل کنند.با بهرهگیری از تراشه NVSwitch، هر کارت گرافیک Hopper انویدیا در یک سرور میتواند بهطور همزمان با هر کارت گرافیک Hopper دیگر، با سرعت 900 GB/s، داده مبادله کند. در فناوری NVSwitch تعداد GPUهای متصل تأثیری بر نرخ انتقال داده نمیگذارد؛ به عبارت دیگر، NVSwitch از نوع غیرمسدودکننده (non-blocking) است. پهنای باند دوطرفه هر تراشه NVSwitch بهشکل چشمگیری به 25.6 Tb/s میرسد.
مقایسه NVLink و NVSwitch

درحالیکه NVLink برای ارتباط مستقیم بین دو یا چند GPU طراحی شده است، NVSwitch بهعنوان یک سوئیچ مرکزی برای مدیریت ارتباطات بین تعداد بیشتری GPU عمل میکند. فناوری NVLink برای ارتباطات نقطهبهنقطه با پهنای باند بالا مناسب است، در حالی که NVSwitch امکان مقیاسپذیری بیشتر را در سیستمهای بزرگ فراهم میکند. بهعنوان مثال، ترکیب NVLink و NVSwitch در سرورهای گرافیکی پیشرفته مانند NVIDIA HGX SXM5 H100 8-GPU، امکان اتصال پرسرعت چندین پردازنده گرافیکی را فراهم میکند و یک محیط عملکرد ابررایانه مانند در مراکز داده ایجاد میکند که تبادل سریعتر داده و مقیاسپذیری حجم کار را تسهیل میکند.
تأثیر فناوریهای NVLink و NVSwitch در حوزههای مختلف
تأثیر NVLink و NVSwitch بر محاسبات با کارایی بالا (HPC)
فناوریهای NVLink و NVSwitch تأثیر قابلتوجهی بر عملکرد سیستمهای HPC داشتهاند. با افزایش پهنای باند و کاهش تأخیر در ارتباطات بین GPUها، فناوریهای NVLink و NVSwitch امکان اجرای سریعتر و کارآمدتر برنامههای محاسباتی پیچیده را فراهم کردهاند. بهعنوان مثال، در سرورهای گرافیکی گیگابایت G492-ID0 4U DP HGX A100 8-GPU، فناوری NVSwitch بهعنوان یک سوئیچ داخلی عمل میکند و اتصال بین کارتهای گرافیک را مدیریت میکند، که موجب بهبود هماهنگی و افزایش سرعت پردازش دادهها میشود.
تأثیر NVLink و NVSwitch بر عملکرد سیستمهای هوشمصنوعی
فناوریهای NVLink و NVSwitch تأثیر بسزایی در بهبود عملکرد سیستمهای هوشمصنوعی داشتهاند. افزایش پهنای باند و کاهش تأخیر در ارتباطات بین GPUها، فرآیند آموزش مدلهای یادگیری عمیق سریعتر و کارآمدتر کردهاند. برای مثال، سیستمهای مجهز به NVSwitch این امکان را فراهم میکنند که چندین مدل پیچیده با حجم دادههای بزرگ بهصورت همزمان اجرا شوند؛ موضوعی که روند تحقیق و توسعه در حوزه هوشمصنوعی را سرعت میبخشد.
چالشها و آینده فناوریهای NVLink و NVSwitch
با وجود مزایای فراوان، فناوریهای NVLink و NVSwitch با چالشهایی نیز مواجه هستند. یکی از این چالشها، نیاز به طراحیهای سختافزاری پیچیدهتر و هزینههای بالاتر است. بهعنوان مثال، کارت گرافیک NVIDIA H100 NVL Tensor Core GPU با بهرهگیری از فناوری NVLink و معماری Hopper، عملکرد بالاتر و زمان پردازش سریعتری را برای مدلهای بزرگ و بارهای سنگین فراهم میآورد، که نشاندهنده پیشرفتهای آینده در این حوزه است.
فناوریهای NVLink و NVSwitch؛ تقویت استنتاج مدلهای زبانی بزرگ با عملکرد فوق سریع

مدلهای زبان بزرگ (LLM) در حال بزرگتر شدن هستند که این امر مقدار محاسبات مورد نیاز برای پردازش درخواستهای استنتاج را افزایش میدهند. برای دستیابی به محدودیتهای بدون وقفه برای سرویسدهی به مدلهای زبان بزرگ (LLM) امروزی و ارائه این سرویس به حداکثر تعداد کاربران ممکن، استفاده از سامانههای چند GPU یک ضرورت اجتنابناپذیر است. تأخیر کم در پاسخگویی تجربه کاربری را بهبود میبخشد. توان عملیاتی بالا هزینه سرویسدهی را کاهش میدهد. هر دو بهطور همزمان از اهمیت بالایی برخوردارند.
حتی اگر یک مدل بزرگ بتواند در حافظه یک GPU پیشرفته و بهروز جای بگیرد، میزان سرعتی که آن GPU میتواند توکن تولید کند، به کل محاسبات موجود برای پردازش درخواستها بستگی دارد. با ترکیب قابلیتهای محاسباتی چندین پردازنده گرافیکی پیشرفته، دستیابی به تجربه کاربری بدون وقفه برپایه جدیدترین مدلها امکانپذیر است.
جمعبندی
فناوریهای NVLink و NVSwitch انویدیا، انقلابی در ارتباطات بین پردازندههای گرافیکی ایجاد کردهاند. این فناوریها با افزایش پهنای باند و کاهش تأخیر، امکان پردازشهای سریعتر و کارآمدتر را در حوزههای هوشمصنوعی و محاسبات با کارایی بالا فراهم کردهاند. ادامه توسعه و بهبود NVLink و NVSwitch، چشماندازی روشن را برای مراکز داده و سیستمهای محاسباتی رقم میزند.
برای دریافت مشاوره تخصصی و انتخاب بهترین سخت افزار متناسب با نیازهای کسبوکار خود، با تیم مجرب ما تماس بگیرید. تیم متخصص و مجرب HPN، بهعنوان منبعی معتبر در حوزه سختافزار و هوشمصنوعی، راهکارهای سفارشی و بهروز را مستقیماً به شما ارائه میدهد.

- تفاوت تکنولوژی کولینگ فن پردازنده نوکتوا با سایر فنها

- کارت شبکه هوشمند (SmartNIC) چیست؟

- معرفی سوپرتراشه RTX SPARK
- راهنمای کامل انتخاب و خرید سرور Dell
- مقدمهای جامع بر هوش مصنوعی: تعریف، تاریخچه، رشد فناوری و مسیر تکامل
- بررسی و معرفی نرم افزار HP ZCentral Remote Boost

- پلتفرم NVIDIA EGX؛ انقلابی در پردازش لبه

- هسته تنسور (Tensor core) در کارتهای گرافیک NVIDIA چیست؟ + کاربردها و عملکرد





