پلتفرم NVIDIA HGX، پیشتاز برای محاسبات هوش مصنوعی در سطح جهانی
امروزه که حجم دادهها و پیچیدگی محاسبات بهسرعت رو به افزایش است، نیاز به زیرساختهای قدرتمند و منعطف در حوزه هوش مصنوعی (AI)، یادگیری عمیق (Deep Learning) و شبیهسازیهای علمی بیش از هر زمان دیگری احساس میشود.
پلتفرم NVIDIA HGX با ترکیب جدیدترین معماریهای پردازندههای گرافیکی، حافظههای پرسرعت و فناوریهای ارتباطی پیشرفته راهکاری جامع برای مدیریت و پردازش همزمان حجم عظیمی از دادهها ارائه میکند. این پلتفرم با تمرکز بر سرعت، مقیاسپذیری و امنیت، نهتنها زمان آموزش و استنتاج مدلهای هوش مصنوعی (AI Inference) را بهطور چشمگیری کاهش میدهد، بلکه با ایجاد زیرساختی انعطافپذیر، امکان ارتقای آسان سیستم و بهرهمندی از نوآوریهای آتی را نیز فراهم میسازد. در ادامه، با بررسی جزئیات فنی و مزایای کلیدی این پلتفرم، درک عمیقتری از نقش آن در تحول دیجیتال و توسعه راهکارهای پیشرفته هوش مصنوعی بهدست خواهیم آورد.

پلتفرم HGX؛ نوآوری در پردازش دادهها
سرورهای پلتفرم NVIDIA HGX بهواسطه فناوریهای نوین، فرایند پردازش دادهها را دگرگون کردهاند. در محیطهای پرترافیک مانند مراکز داده ابری (Cloud Data Center) ، چتباتها (chatbots) و دستیارهای هوش مصنوعی (AI assistants) ، تحلیل دادههای بدون توقف، کاهش تأخیر و افزایش دقت نقش اساسی در بهبود تجربه کاربری دارند. این تحول دیجیتال نهتنها باعث افزایش بهرهوری و کاهش هزینههای عملیاتی میشود، بلکه زمینه را برای نوآوریهای بیشتر در حوزههای مختلف مانند اینترنت اشیا (IOT) ، پردازش زبان طبیعی (NLP) و حتی مدلهای زبان بزرگ (LLM) فراهم میآورد.
آشنایی با پلتفرم ماژولار NVIDIA HGX از نگاه ساده تا تخصصی
پلتفرم NVIDIA HGX، درواقع یک زیرساخت ماژولار هستند که چندین پردازنده گرافیکی قدرتمند را در کنار هم قرار میدهند و با استفاده از فناوریهای ارتباطی پرسرعت به آنها امکان میدهند دادهها را با حداقل تأخیر و بالاترین پهنای باند تبادل کنند. این پلتفرم برای اجرای بارهای محاسباتی سنگین در حوزههایی مانند هوش مصنوعی(AI)، یادگیری ماشین(Machin Learning)، یادگیری عمیق(Deep Learning) و شبیهسازیهای علمی طراحیشده است و میتواند با افزایش تعداد ماژولهای پردازنده گرافیکی، بهصورت مقیاسپذیر گسترش یابد. مهمترین مزیت پلتفرم NVIDIA HGX، ترکیب معماریهای جدید پردازنده گرافیکی، حافظههای پرسرعت (مانند HBM) و ارتباطات میانپردازندهای قدرتمند است که درمجموع، سرعت و کارایی محاسباتی را به شکل چشمگیری ارتقا میدهد.

نمای فیزیکی HGX A100 با ۸ پردازنده گرافیکی
در این تصویر، یک برد ماژولار از سری HGX انویدیا مشاهده میشود که چندین ماژول GPU قدرتمند با سوکت SXM بر روی آن نصب شدهاند و بااتصالهای پرسرعت (نظیر NVLink و NVSwitch) به یکدیگر متصل شدهاند. طراحی فشرده و ماژولار این برد، با قرارگیری کارتهای گرافیکی در فاصله نزدیک و بهرهمندی از سیستم خنککننده اختصاصی، نشاندهندهی هدف آن برای محاسبات سنگین HPC، آموزش مدلهای هوشمصنوعی عظیم و پردازش موازی در مراکز داده پیشرفته است. ترکیب چیدمان عمودی خنککنندهها و رادیاتورهای بزرگ (Heat Sink) نیز حاکی از اهمیت مدیریت گرما در بارهای کاری فوق سنگین است و این معماری، بهویژه برای سازمانها یا پژوهشگاههایی که نیاز به حداکثر کارایی در کمترین فضای ممکن دارند، طراحیشده است.
توضیح تخصصی NVIDIA HGX:
این پلتفرم بر پایه آخرین نسل GPUها مانند (H200 & H100) و فناوری پلهای ارتباطی پرسرعت مانند NVLink طراحیشده است. با فراهم کردن ارتباط مستقیم و پهنای باند بسیار بالا بین کارتهای گرافیک، انتقال دادهها را بدون تأخیر و با کارایی بالا تضمین میکند. علاوه بر این، معماری ماژولار HGX امکان مقیاسپذیری و ارتقا را بهطور پویا فراهم میآورد؛ امری که در محیطهای دیتاسنترهای پیشرفته و پروژههای هوش مصنوعی حیاتی است. در ادامه به بررسی تخصصیتر این پلتفرم میپردازیم.
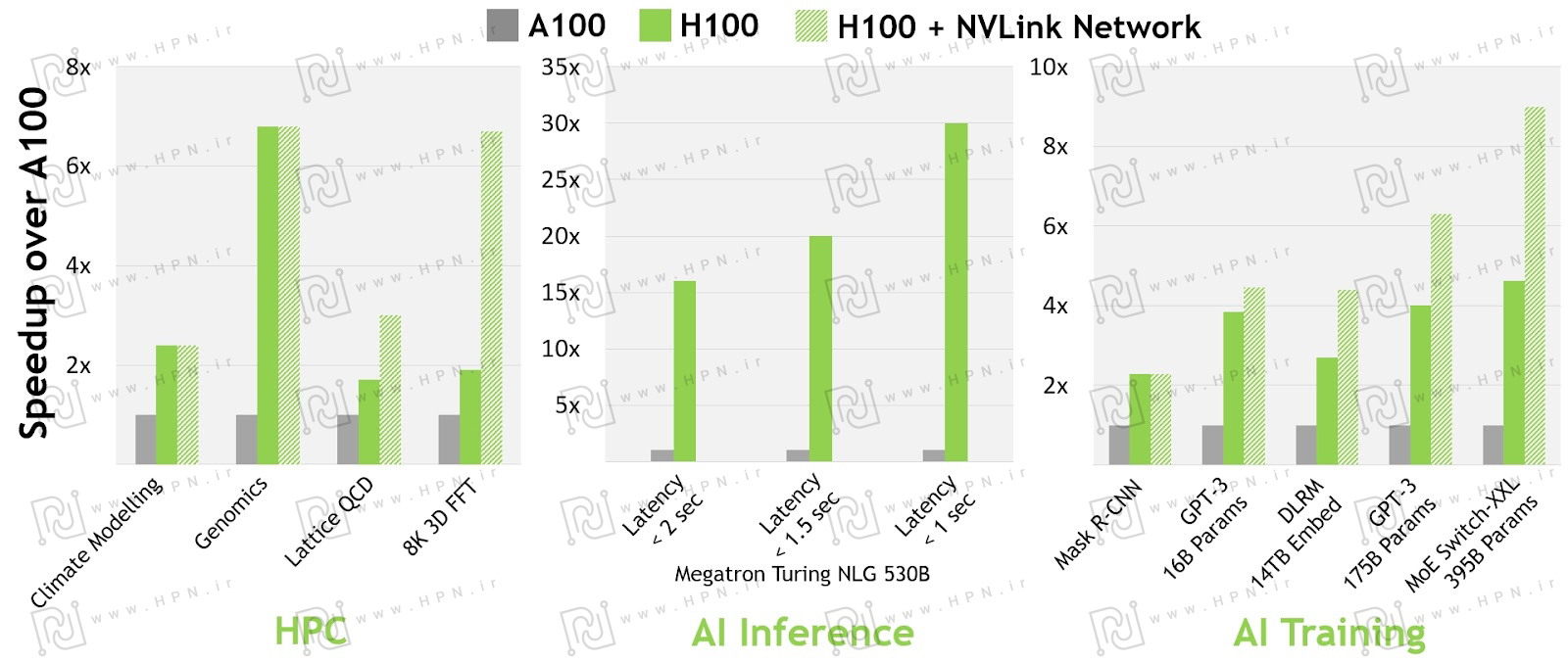
این تصویر عملکرد مدلهای مختلف NVIDIA HGX، از جمله A100 ، H100 و H100 +NVLink، را در سه حوزه مختلف مقایسه میکند:
| آموزش مدلهای هوش مصنوعی (AI Training)
– در آموزش مدلهایی مانند Mask R-CNN، GPT-3 (16B و 175B پارامتر)، DLRM (با 14TB Embed) و MoE Switch-XXL (395B پارامتر) ، H100 بین ۲ تا ۵ برابر سریعتر از A100 است. – استفاده از NVLink در مدلهای بزرگتر مانند MoE Switch-XXL موجب افزایش بیش از ۹ برابری سرعت نسبت به A100 میشود. |
استنتاج هوش مصنوعی (AI Inference)
– برای مدل Megatron Turing NLG 530B، پردازنده H100 تا ۲۰ برابر سریعتر از A100 عمل میکند. – در سناریوهایی که نیاز به کاهش تأخیر زیر ۲، ۱.۵ و ۱ ثانیه دارند، عملکرد H100 به ۳۰ برابر نیز میرسد. – این قسمت از نمودار نشان دهنده پیشرفت چشمگیر مدل H100 نسبت به نسل قبلی است. |
محاسبات با کارایی بالا (HPC) – در مدلسازی اقلیمی(Climate modelling)، ژنومیکس(Genomics)، کرومودینامیک کوانتومی شبکه ای (Lattice QCD) و تبدیل سریع سهبعدی (به اختصار 3D FFT)، شتاب عملکردی H100 نسبت به A100 ۲ تا ۷ برابر است. – اضافه شدن NVLink در برخی از این کاربردها به افزایش سرعت کمک میکند، در ژنومیکس و تبدیل سریع سهبعدی(3D FFT) به بیش از ۶ برابر میرسد. |
پردازنده H100 نسبت به A100 در تمام حوزهها بهبود چشمگیری دارد، مخصوصاً در استنتاج مدلهای زبانی که افزایش سرعت تا ۳۰ برابر مشاهده میشود. همچنین، شبکه NVLink تأثیر قابلتوجهی در کاهش زمان آموزش مدلهای بزرگ دارد.
ویژگیهای کلیدی پلتفرم NVIDIA HGX
پلتفرم NVIDIA HGX یکی از قدرتمندترین راهکارهای سختافزاری برای پردازشهای هوش مصنوعی (AI)، یادگیری عمیق (Deep Learning) و محاسبات با کارایی بالا (HPC) است. این پلتفرم ترکیبی از پردازندههای گرافیکی (GPU) پیشرفته، فناوریهای ارتباطی پرسرعت و نرمافزارهای بهینهسازی شده را ارائه میدهد. برخی از ویژگیهای کلیدی این پلتفرم:
۱. قدرت پردازشی فوقالعاده
- پلتفرم HGX از جدیدترین GPUهای سری NVIDIA H100 و A100 بهره میبرد که برای حجمهای کاری سنگین در یادگیری عمیق و HPC طراحی شدهاند.
۲. ارتباطات سریع و مقیاسپذیر
- استفاده از فناوریهای NVIDIA NVLink و NVSwitch به GPU ها اجازه میدهد تا با یکدیگر در ارتباط باشند و پهنای باند بالایی را ارائه دهند.
- PCIe Gen5 و شبکههای NVIDIA Quantum-2 InfiniBand سرعت ارتباطات بین پردازندهها و حافظه را افزایش میدهند، که در عملکرد کلی سیستم تأثیر بسزایی دارد.
۳. بهینهسازی برای هوش مصنوعی و HPC
- پلتفرم HGX بهطور خاص برای پردازش مدلهای بزرگ هوش مصنوعی (AI) و یادگیری ماشین (ML) طراحی شده است.
- عملکرد بهینه برای آموزش دادن مدلهای (GPT-4 ,BERT ,Megatron) و (Transformer)، باعث کاهش زمان آموزش و افزایش بهرهوری میشود.
۴. بهرهوری انرژی بالا
- معماری پلتفرم HGX با مصرف بهینهی انرژی طراحی شده است و نسبت عملکرد به مصرف انرژی (Performance per Watt) بالایی دارد.
- این ویژگی باعث کاهش هزینههای عملیاتی (OPEX) در دیتاسنترها و مراکز تحقیقاتی میشود.
۵. مقیاسپذیری بالا برای مراکز داده
- امکان استفاده در سرورهای ۴-GPU-۸ ،GPU و سیستمهای ماژولار، بسته به نیاز سازمانها برای حجمهای کاری مختلف.
- مناسب برای مراکز دادههای تحقیقاتی، ابررایانهها، و ارائهدهندگان خدمات ابری (Cloud Computing) میباشد.
۶. پشتیبانی از اکوسیستم نرمافزاری NVIDIA
- سازگاری با NVIDIA CUDA، cuDNN، TensorRT، RAPIDS و Triton Inference Server برای اجرای بهینهی پردازشها.
- پشتیبانی از NVIDIA AI Enterprise که توسعه و استقرار مدلهای هوش مصنوعی را در مقیاس سازمانی سادهتر میکند.
برای دریافت مشاوره تخصصی و انتخاب بهترین سرور هوش مصنوعی متناسب با نیازهای کسبوکار خود، با تیم مجرب ما تماس بگیرید. شرکت ما بهعنوان منبع معتبر در حوزه سختافزار و هوش مصنوعی آماده ارائه راهکارهای سفارشی و بهروز به شما است.
به کارگیری پلتفرم HGX؛ یکپارچگی و انعطافپذیری در معماریهای چندسازنده
امکان بهرهبرداری از پلتفرم HGX بر روی سرورهای ارائهشده توسط برندهای معتبر مانند Lenovo ،Apollo ،Dell و Supermicro نمونهای بارز از تلفیق هوشمندانه سختافزار و نرمافزار در محیطهای محاسباتی با کارایی بالاست. معماری ماژولار HGX، با بهکارگیری فناوریهای ارتباطی پیشرفته مانند NVLink و NVSwitch و استفاده از پردازندههای گرافیکی نسل جدید مانند ( NVIDIA Tesla A100 ،H200 و H100) انتقال دادهها را بدون تأخیر و با پهنای باند بالا تضمین میکند. این انعطافپذیری، امکان ادغام یکپارچه HGX در سرورهای متنوع را فراهم میآورد؛ بدین ترتیب، مدیران فناوری اطلاعات میتوانند با ترکیب بهینه سختافزارهای چندسازنده از برندهای مختلف، زیرساختهای مقیاسپذیر و مطمئنی را جهت پردازشهای سنگین هوش مصنوعی، یادگیری عمیق و شبیهسازیهای علمی به اجرا درآورند. بر اساس مستندات فنی منتشرشده توسط NVIDIA و تجربیات عملی در بهرهبرداری از سرورهای Lenovo، Apollo و Dell این رویکرد بهبود چشمگیری در عملکرد محاسباتی و کاهش زمان پاسخگویی به بارهای کاری پیچیده ایجاد میکند.

نکات کلیدی در بهرهبرداری از سرورهای هوش مصنوعی
هوش مصنوعی برای حل چالشهای متنوع تجاری از شبکههای عصبی متنوعی استفاده میکند. یک شتابدهنده استنتاج هوش مصنوعی عالی نهتنها باید بالاترین عملکرد را ارائه دهد، بلکه باید انعطافپذیری لازم برای شتابدهی این شبکهها در هر مکانی که مشتریان تصمیم به استقرار آن بگیرند (از مرکز داده تا لبه شبکه) را نیز داشته باشد.
ازاینرو برای انتخاب سرور مناسب هوش مصنوعی، مدیران و متخصصین باید موارد زیر را مدنظر قرار دهند:
- تعیین نیازهای پروژه:
تحلیل دقیق از بارکاری، حجم دادهها و الگوریتمهای مورد استفاده به انتخاب سرور صحیح کمک میکند.
- انتخاب GPU مناسب:
ارزیابی مدلهای مختلف مانند Tesla A100 یا H100 که برای پردازش موازی و اجرای سریع الگوریتمهای پیچیده بهینه شدهاند.
- قابلیت مقیاسپذیری:
اطمینان از اینکه سرور انتخابی قابلیت ارتقا و افزایش منابع بهصورت پویا را دارد.
- امنیت و پشتیبانی فنی:
انتخاب ارائهدهندهای که پشتیبانی فنی قوی و خدمات پس از فروش مناسب را ارائه دهد، ازجمله الزامات مهم در انتخاب زیرساختهای هوش مصنوعی.
آینده هوش مصنوعی با HGX در دستان شماست
با توجه به نیازهای روزافزون به راهکارهای هوش مصنوعی و یادگیری ماشین، انتخاب زیرساختهای پردازشی کارآمد و نوین از اهمیت ویژهای برخوردار است. سرورهای پلتفرم NVIDIA HGX با ارائه سرعت بالا، بهینهسازی منابع، امنیت مطمئن و مقیاسپذیری فوقالعاده، بهعنوان ستون فقرات پروژههای پیشرفته دیجیتال مطرح میشوند. اگر بهدنبال تحول در دنیای پردازش دادهها و دستیابی به نوآوریهای دیجیتال هستید، این سرورها گزینهای ایدهآل برای سازمانها و مدیران فناوری اطلاعات بهحساب میآیند.
برای دریافت مشاوره تخصصی و انتخاب بهترین پلتفرم هوش مصنوعی متناسب با نیازهای کسبوکار خود، با متخصصان ما تماس بگیرید. شرکت ما بهعنوان منبع معتبر در حوزه سختافزار و هوش مصنوعی آماده ارائه راهکارهای سفارشی و بهروز به شما است.

نوشتههای مرتبط
بررسی و معرفی نرم افزار HP ZCentral Remote Boost
پلتفرم NVIDIA EGX؛ انقلابی در پردازش لبه
هسته تنسور (Tensor core) در کارتهای گرافیک NVIDIA چیست؟ + کاربردها و عملکرد
معماری NVIDIA در گذر زمان؛ بررسی نسلهای GPU انویدیا | تاریخچه + ویژگیها
فناوریهای NVLink و NVSwitch
سوکت SXM و نقش کلیدی آن در پردازندههای گرافیکی و سیستمهای پردازشی مدرن
بررسی و معرفی پلتفرم ماژولار NVIDIA HGX
بررسی تخصصی انویدیا DGX

تفاوت RAM و ROM

راهنمای خرید مانیتور HP

کارت گرافیک NVIDIA Quadro NVS 810

راهنمای جامع خرید پردازنده برای گیمرها
- بررسی و معرفی نرم افزار HP ZCentral Remote Boost

- پلتفرم NVIDIA EGX؛ انقلابی در پردازش لبه

- هسته تنسور (Tensor core) در کارتهای گرافیک NVIDIA چیست؟ + کاربردها و عملکرد

- معماری NVIDIA در گذر زمان؛ بررسی نسلهای GPU انویدیا | تاریخچه + ویژگیها

- فناوریهای NVLink و NVSwitch

- سوکت SXM و نقش کلیدی آن در پردازندههای گرافیکی و سیستمهای پردازشی مدرن

- بررسی و معرفی پلتفرم ماژولار NVIDIA HGX

- بررسی تخصصی انویدیا DGX
