معرفی هستههای تنسور: تسریع هوش مصنوعی با نوآوری انویدیا

با گسترش روزافزون کاربردهای هوش مصنوعی و افزایش پیچیدگی گرافیکی بازیهای ویدیویی، کارتهای گرافیک دیگر فقط مخصوص نمایش تصویر نیستند. در پاسخ به این نیاز، شرکت انویدیا با معرفی هستههای تنسور (Tensor Cores) در معماریهای جدید کارتهای گرافیکی خود، گام بزرگی در افزایش توان محاسباتی برداشته است.
Tensor Core ها عملکردی بینظیر در طیف وسیعی از وظایف هوش مصنوعی و پردازشهای محاسباتی سنگین (HPC) ارائه میدهند. این هستهها قلب تپندهی فناوریهایی مانند DLSS و موتورهای یادگیری عمیق هستند و حالا از لپتاپهای خانگی تا ابرکامپیوترها در سراسر جهان به کار گرفته میشوند. اما این هستهها دقیقاً چه میکنند؟ چرا اهمیت دارند؟ و چگونه دنیای گرافیک و هوش مصنوعی را متحول کردهاند؟
در این مقاله، با زبانی ساده، به بررسی ساختار و نقش حیاتی هستههای تنسور در معماریهای مختلف انویدیا میپردازیم.
Tensor چیست و چرا برای پردازشهای هوش مصنوعی اهمیت دارد؟
در ریاضیات، تنسور (Tensor) ساختاری جبری است که برای نمایش و تحلیل روابط میان مجموعهای از اشیای ریاضی بهکار میرود که همگی بهنوعی با یکدیگر مرتبطاند. بهبیان سادهتر، میتوان تنسور را مانند ظرفی در نظر گرفت که دادهها را در ابعاد مختلف ذخیره و پردازش میکند.
تنسورها اغلب با ماتریس اشتباه گرفته میشوند؛ در حالیکه ماتریس تنها نمونهای دوبعدی از یک تنسور است. در واقع، تنسورها تعمیمیافتهی ماتریسها به فضاهای چندبعدی (n-بعدی) هستند. اما نقش تنسورها تنها به نگهداری دادهها محدود نمیشود. آنها همچنین امکان انجام تبدیلات خطی پیچیدهای مانند ضرب داخلی و خارجی میان تنسورها را فراهم میکنند که در بسیاری از محاسبات علمی، گرافیکی و هوش مصنوعی کاربرد حیاتی دارند.
عملیات ماتریسی و چالشهای محاسباتی
یکی از مهمترین عملیات ریاضی روی تنسورها، ضرب ماتریسی است. برای مثال:
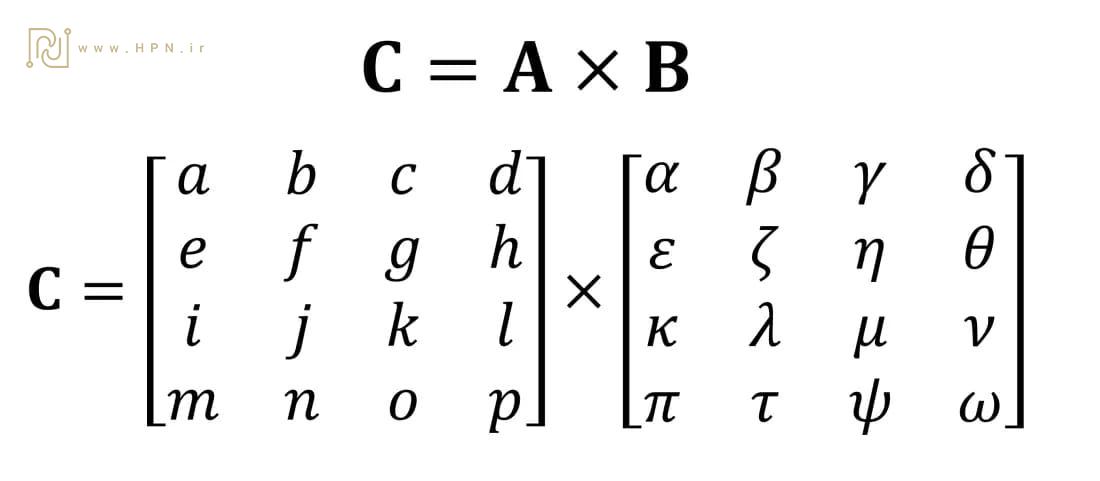
- ضرب دو ماتریس ۴×۴ شامل ۶۴ عمل ضرب و ۴۸ عمل جمع است.
- محصول نهایی ضرب ماتریسها، ماتریسی خواهد بود که تعداد سطرهایش برابر با تعداد سطرهای ماتریس اول و تعداد ستونهایش مطابق با تعداد ستونهای ماتریس دوم است. به همین دلیل، باید روشی مناسب برای انجام این عملیات به کار گرفت. در تصویر زیر، چگونگی اجرای این فرآیند به نمایش درآمده است.

- نتایج میانی باید در حافظه پنهان (cache) ذخیره و سپس با حاصلضربهای دیگر جمع شوند.
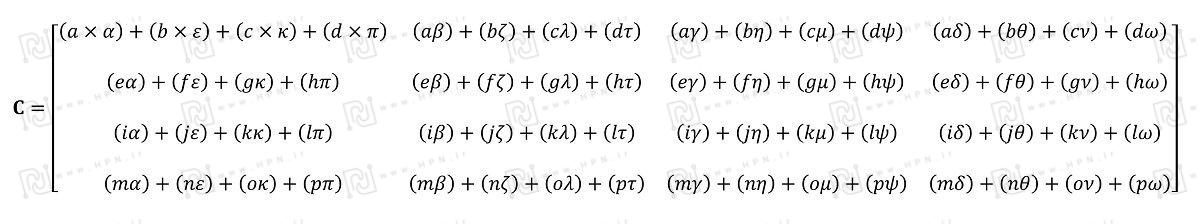
بنابراین گرچه ضربهای ماتریسی ازنظر ریاضی ساده هستند اما ازنظر محاسباتی به تعداد و مقدار زیادی از ثباتها و حافظه پنهان جهت خواندن و نوشتن نیاز دارند.
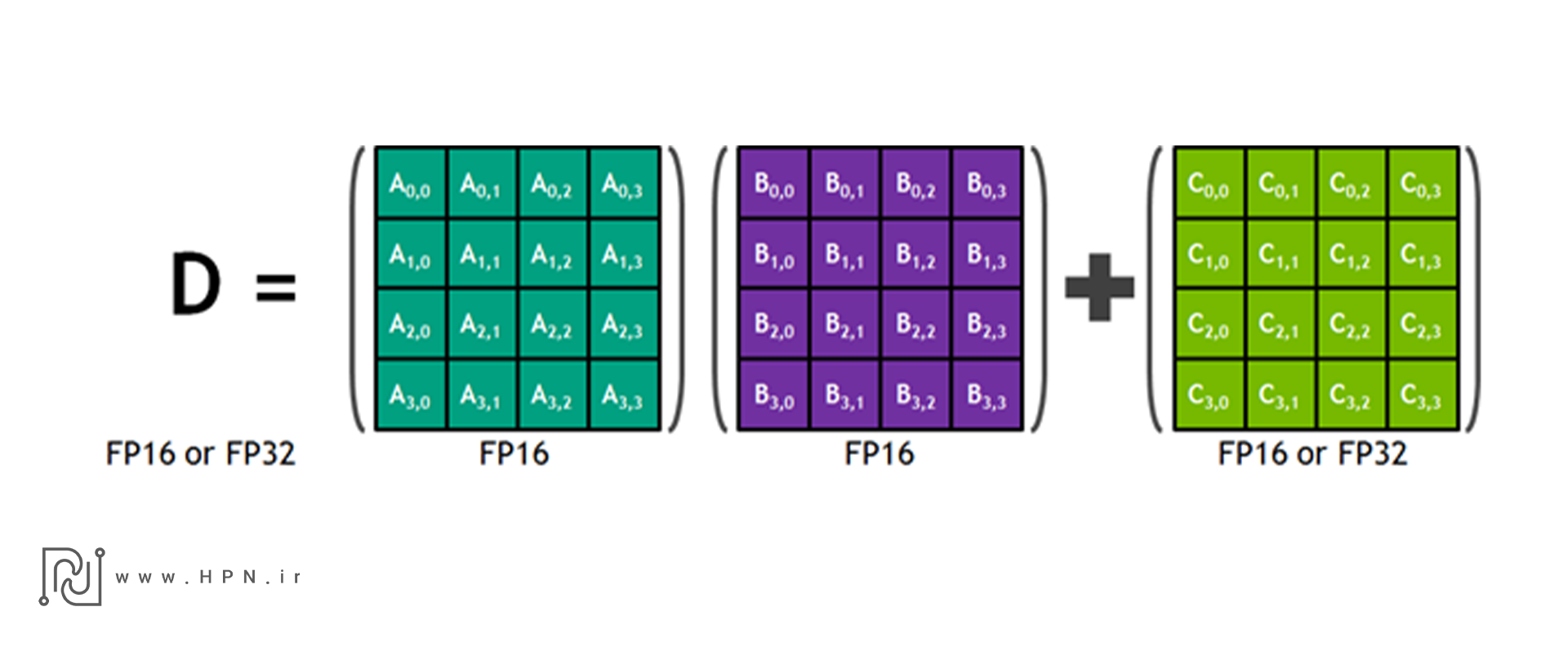
در این شماتیک، یک عملیات پایهای Matrix Multiply–Accumulate (MMA) که توسط Tensor Core های انویدیا اجرا میشود، نمایش داده شده است:
D=A×B+C
- ماتریسهای A و B هرکدام با ابعاد 4×4 و عناصر FP16 (نقطهشناور ۱۶ بیتی) وارد هسته میشوند.
- ضرب این دو ماتریس بهصورت سختافزاری در Tensor Core انجام شده و حاصل آن با ماتریس C جمع میشود.
- ماتریس C و نتیجه نهایی D میتوانند بهصورت FP16 یا FP32 (نقطهشناور ۳۲ بیتی) انباشته شوند؛ انتخاب دقت بالاتر (FP32) برای موقعیتهایی است که کاهش خطا اهمیت بیشتری دارد.
نقش هستههای تنسور در دنیای دیجیتال
در دنیای کامپیوتر بسیاری از دادهها از قبیل یک متغیر، یک فایل صوتی یا یک تصویر سیاه و سفید یا رنگی در قالب Tensorها ذخیره میشوند.
کمپانیهای Intel و AMD طی این سالها نسخههای مختلفی از پردازندهها را برای انجام این کار ارائه دادهاند.

اما نوع خاصی از پردازندهها وجود دارند که بهطور ویژه برای مدیریت عملیات SIMD (Multiple Data Single Instruction) یا یک دستور چند داده طراحی شدهاند: واحدهای پردازش گرافیک (GPU)
هستههای Tensor در GPU چگونه عمل میکند؟
قابلیت پردازش موازی GPUها که توسط CUDA COREها انجام میشود آنها را برای مدیریت Tensor Coreها ایدهآل میکند.
ازلحاظ عملکرد یک هسته CUDA مشابه یک هسته CPU است با این تفاوت که تعداد هستههای CUDA بهمراتب خیلی بیشتر از هستههای CPU است. هر هسته CUDA میتواند حداکثر یک عمل جمع/ضرب را انجام دهد.
در دسامبر سال 2017، کمپانی NVIDIA اولین پردازنده گرافیکی مبتنی بر معماری Volta با نام TITAN V را معرفی کرد.
 چیزی که این پردازنده گرافیکی را خاص میکرد وجود هستههایی مختص محاسبات تنسورها به نام Tensor CORE بود.
چیزی که این پردازنده گرافیکی را خاص میکرد وجود هستههایی مختص محاسبات تنسورها به نام Tensor CORE بود.
هر هسته تنسور توانایی انجام چند عمل در هر clock cycle را دارد که باعث سرعت بخشیدن به فرآیند یادگیری مدلهای پیچیده هوش مصنوعی و یادگیری عمیق و همچنین اجرای بازیهای جدید که از قابلیت DLSS و Ray Tracing پشتیبانی میکنند میشود.
پس از سری ولتا انویدیا در معماریهای بعدی خود مثل TURING و AMPERE سعی در بهبود سرعت، دقت و اندازه Tensor Coreها در هر پردازنده گرافیکی دارد که موجب تحولی عمیق در حوضه محاسبات سطح بالا(HPC)، هوش مصنوعی(AI) و صنعت بازیهای ویدیویی شده است.
کارتهای گرافیک مدرن مانند سری NVIDIA RTX و A100 دارای هزاران هسته CUDA و صدها هسته Tensor هستند که به اجرای سریعتر الگوریتمهای یادگیری ماشین و شبکههای عصبی کمک میکنند.
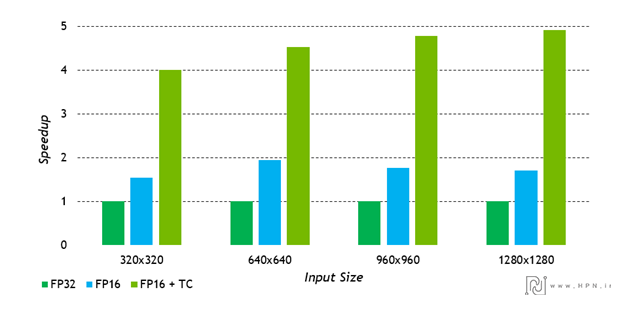
در این نمودار نشان میدهد که هستههای تنسور میتوانند سرعت پردازش را بهطور چشمگیری افزایش دهد (بهویژه در اندازههای ورودی بزرگتر). این مزیت برای کاربردهایی مانند یادگیری عمیق، پردازش تصویر، و بازیهای با رزولوشن بالا مانند استفاده در DLSS بسیار حیاتی است، زیرا هم سرعت را بالا میبرد و هم مصرف انرژی را بهینه میکند.
درنتیجه برای بارهای کاری ماتریسی با ابعاد بزرگ (مثل لایههای کانولوشن یا ماتریسهای وزن در شبکههای عصبی عمیق)، فعالسازی Tensor Core میتواند تا تقریباً 5× سرعت بیشتر نسبت به اجرای معمولی داشته باشد.
نسلهای مختلف هستههای تنسور
نسل اول هستههای تنسور: Volta (2017) – آغاز انقلاب
این هستهها توانستند بهبود چشمگیری در عملکرد ضرب ماتریسها ایجاد کنند بهطوریکه فرآیند آموزش (Training) را تا 12TFLOPS و فرآیند استنتاج کردن را تا 6TFLOPS نسبت به معماری Pascal بهبود بخشند. این قابلیتهای کلیدی به Volta این امکان را میدهد تا بهطورکلی عملکرد خود را تا 3 برابر نسبت به Pascal افزایش دهد.
ویژگی برجسته:
اولین نسخه از Tensor Coreها که در Tesla V100 معرفی شد. عملکرد فوقالعادهای در آموزش مدلهای یادگیری عمیق با دقت FP16 داشت و تا 12 برابر افزایش سرعت نسبت به هستههای معمولی ارائه داد.
کاربرد اصلی: آموزش مدلهای پیچیدهی یادگیری عمیق.
نسل دوم هستههای تنسور : Turing (2018) – ورود به دنیای استنتاج
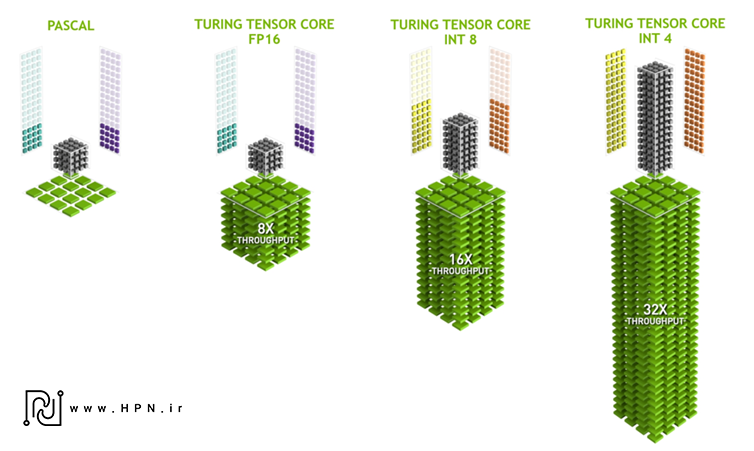
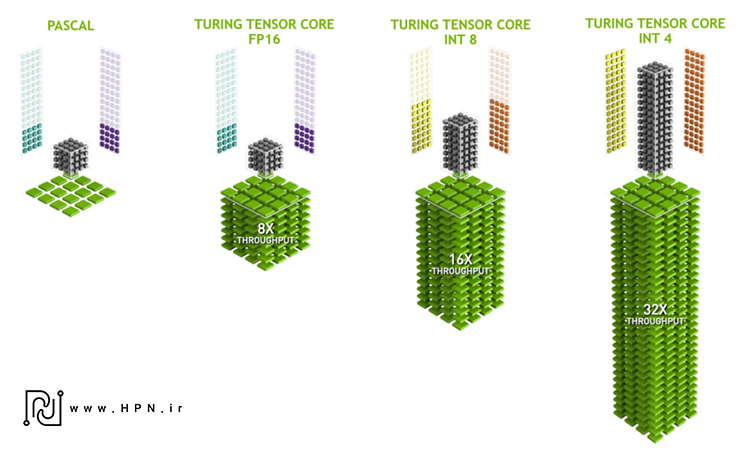 این هستهها برای استنتاج و یادگیری روشهای مبتنی بر هوش مصنوعی از فرمتهای عددی FP32، FP16، INT8، INT4 برای ایجاد جهشهای عظیم در عملکرد نسبت به پردازندههای گرافیکی پاسکال استفاده کردند.
این هستهها برای استنتاج و یادگیری روشهای مبتنی بر هوش مصنوعی از فرمتهای عددی FP32، FP16، INT8، INT4 برای ایجاد جهشهای عظیم در عملکرد نسبت به پردازندههای گرافیکی پاسکال استفاده کردند.
ویژگی برجسته:
اضافه شدن پشتیبانی از عملیات عدد صحیح INT8 و INT4 برای بهینهسازی فرآیند استنتاج (Inference) در مدلهای از پیش آموزشدیده.
کاربرد اصلی: اجرای مدلهای یادگیری ماشین در زمان واقعی، مناسب برای بازی و پردازشهای تعاملی.
________________________________________
نسل سوم هستههای تنسور: Ampere (2020) – انعطافپذیری و کارایی بیشتر
در این معماری شاهد نسل سوم هستههای Tensor بودیم. در این معماری انویدیا دقتها و فرمتهای عددی جدیدی را برای پوشش طیف کاملی از نیازهای محققان فراهم میکند. که شامل فرمتهای عددی TF32, FP64, FP16, INT8, INT4 میباشد که با این افزایش قدرت هستههای Tensor انویدیا سعی در سادهسازی و تسریع فرایندهای مرتبط با هوش مصنوعی و HPC دارد.
ویژگی برجسته:
معرفی TF32 (TensorFloat-32) برای تسریع آموزش بدون نیاز به تغییر در کد. همچنین پشتیبانی از BF16 (Bfloat16) برای تطابق با مدلهای صنعتی و TensorFlow.
کاربرد اصلی: افزایش شتاب آموزش مدلها تا 20 برابر بدون افت دقت.
نسل چهارم هستههای تنسور: NVIDIA Hopper (2022) تمرکز بر FP8

از زمان معرفی فناوری Tensor Core، پردازندههای گرافیکی سری NVIDIA Hopper توانستهاند عملکرد اوج خود را تا ۶۰ برابر افزایش دهند؛ جهشی چشمگیر که مسیر را برای گسترش دسترسی به توان پردازشی در حوزههای هوش مصنوعی و محاسبات سنگین (HPC) هموار کرده است.
معماری Hopper با معرفی نسل چهارم هستههای تنسور و بهرهگیری از موتور Transformer، از دقت FP8 برای دستیابی به سرعتی ۶ برابر بیشتر نسبت به FP16 در آموزش مدلهای عظیم با تریلیونها پارامتر استفاده میکند.
همچنین با ارائه عملکردی تا ۳ برابر بهتر در دقتهای TF32 ،FP64 ،FP16 و INT8 این هستههای پیشرفته شتابی چشمگیر به اجرای انواع بارهای کاری بخشیدهاند.
دقت هستههای تنسور: FP64 ,TF32 ,BF16 ,FP16 ,FP8 ,INT8
ویژگی برجسته:
ورود FP8 بهعنوان دقت جدید برای آموزش مدلهای چند تریلیون پارامتری با کمترین مصرف انرژی.
کاربرد اصلی: شتابدهی مدلهای مولد (Generative AI) نظیر GPT، LLM و Stable Diffusion.
________________________________________
نسل پنجم هستههای تنسور: Blackwell (2024) – نهایت قدرت در AI
معماری Blackwell نسبت به نسل قبلی خود، یعنی NVIDIA Hopper، تا ۳۰ برابر سرعت بیشتری در پردازش مدلهای عظیمی مانند GPT-MoE-1.8T ارائه میدهد. این جهش چشمگیر در عملکرد، به لطف نسل پنجم هستههای تنسور امکانپذیر شده است. Tensor Core ها در معماری Blackwell از دقتهای جدیدی پشتیبانی میکنند، ازجمله فرمتهای میکرومقیاسگذاری که توسط جامعه توسعهدهندگان تعریف شدهاند؛ این فرمتها دقت بالاتر و جایگزینی آسانتری برای دقتهای بالاتر فراهم میکنند.
معماری Blackwell دقتهای FP64, TF32, BF16, FP16, FP8, INT8, FP6, FP4 را برای پشتیبانی از مدلهای تریلیونپارامتری فراهم کرد.
فرمتهای دقت جدید (Precision Formats)
با رشد فزاینده اندازه و پیچیدگی مدلهای هوش مصنوعی مولد، بهبود عملکرد در آموزش و استنتاج به یک ضرورت تبدیلشده است. برای پاسخ به این نیاز محاسباتی، هستههای Tensor در معماری Blackwell از فرمتها و دقتهای کوانتیزاسیون جدیدی پشتیبانی میکنند، ازجمله فرمتهای میکرومقیاسگذاری که توسط جامعه تعریف شدهاند.
موتور Transformer نسل دوم
موتور Transformer نسل دوم با بهرهگیری از فناوری اختصاصی هستههای تنسور در معماری Blackwell و ترکیب آن با نوآوریهای NVIDIA TensorRT-LLM و فریمورک NeMo، سرعت آموزش و استنتاج مدلهای زبانی بزرگ (LLM) و مدلهای Mixture-of-Experts (MoE) را بهطور چشمگیری افزایش میدهد. این موتور با استفاده از دقت FP4 در Tensor Core، عملکرد و بهرهوری را دو برابر کرده و درعینحال دقت بالای مدلهای نسل فعلی و آینده MoE را حفظ میکند.
هدف این موتور، فراهمسازی عملکردی در لحظه برای مدلهای زبانی پیشرفته و درنتیجه دموکراتیزه کردن استفاده از آنهاست. کسبوکارها میتوانند با تکیهبر این فناوری، مدلهای هوش مصنوعی مولد پیشرفته را با هزینهای مقرونبهصرفه پیادهسازی کرده و فرایندهای خود را بهینهسازی کنند.
کاربرد اصلی: مدلهای مولد با بیش از 10 تریلیون پارامتر، استنتاج در مقیاس گسترده، یادگیری ترکیبی.

کاربردهای هستههای تنسور در محاسبات پیشرفته
آموزش انقلابی هوش مصنوعی
آموزش مدلهای مولد با چندین تریلیون پارامتر با دقت ۱۶-بیتی (FP16) ممکن است ماهها زمان ببرد. Tensor Core های انویدیا با استفاده از دقتهای پایینتری مانند FP8 در موتور Transformer، عملکردی چند برابر سریعتر ارائه میدهند. به لطف پشتیبانی مستقیم در فریمورکهای اصلی از طریق کتابخانههای CUDA-X، پیادهسازی این فناوری بهصورت خودکار انجام میشود که به طرز چشمگیری زمان موردنیاز برای رسیدن به همگرایی در آموزش را کاهش میدهد (بدون افت دقت).
جهش بزرگ در استنتاج هوش مصنوعی
دستیابی به تأخیر پایین همراه با بهرهوری بالا و استفاده حداکثری از منابع، مهمترین نیاز برای اجرای مطمئن فرآیند استنتاج (Inference) در هوش مصنوعی است. معماری Blackwell انویدیا با نسل دوم موتور Transformer عملکردی فوقالعاده ارائه میدهد و درعینحال آنقدر انعطافپذیر است که بتواند انواع مدلهای مولد با چندین تریلیون پارامتر را شتاب ببخشد.
Tensor Coreها باعث شدهاند انویدیا در بنچمارکهای معتبر جهانی MLPerf برای استنتاج، رتبه نخست را کسب کند.
ابررایانش پیشرفته (Advanced HPC)
ابررایانش یا HPC یکی از ستونهای اصلی علم مدرن است. دانشمندان برای دستیابی به کشفیات نسل بعد، از شبیهسازیها استفاده میکنند تا مثلا مولکولهای پیچیده را برای کشف دارو، قوانین فیزیک را برای منابع انرژی جدید، و دادههای جوی را برای پیشبینی دقیقتر شرایط آبوهوایی شدید بهتر درک کنند.
Tensor Core های انویدیا با پشتیبانی از طیف گستردهای از دقتها، از جمله FP64، به دانشمندان کمک میکنند تا محاسبات علمی را با بالاترین دقت و سرعت انجام دهند.
همچنین مجموعه نرمافزاری HPC SDK تمام کامپایلرها، کتابخانهها و ابزارهای لازم برای توسعه اپلیکیشنهای HPC بر پایه پلتفرم انویدیا را فراهم میکند.
هستههای Tensor: مزیتی کلیدی در معماری نوین کارتهای گرافیک
هستههای تنسور که به هستههای هوش مصنوعی معروف هستند، عملیات را بر روی ماتریسهای کوچک انجام میدهند. هر Tensor Core میتواند در هر کلاک GPU عملیات جمع/ضرب ماتریسی را انجام دهد، دراین عملیات دو ماتریس در هم ضرب میشوند و نتیجه ضرب آنها با هم جمع و در یک ماتریس بهاندازه ماتریسهای ورودی ذخیره میشود.
با توجه به ماهیت ماتریسی بودن عملیات یادگیری ماشین و بهطور خاص شبکههای عصبی GPUها مناسبترین سختافزار برای یادگیری ماشین هستند. از آنجا که Tensor Coreها بهمنظور انجام محاسبات ماتریسی در کارتهای گرافیکی تعبیه شدهاند میتوان گفت کارتهای گرافیک دارای این هستهها از عملکرد بسیار مناسبی نسبت به سایر کارتهای گرافیک در حوزه یادگیری ماشین و بهطورکلی هوش مصنوعی برخوردار هستند.
اگر مایل هستید با نسلهای مختلف کارتهای گرافیک انویدیا و تحول معماری آنها از ابتدا تا امروز آشنا شوید، پیشنهاد میکنیم مقالهی معرفی کامل معماریهای انویدیا را مطالعه کنید.
برای مشاهده کارت گرافیکهای برند NVIDIA کلیک کنید.

نوشتههای مرتبط
بررسی و معرفی نرم افزار HP ZCentral Remote Boost
پلتفرم NVIDIA EGX؛ انقلابی در پردازش لبه
هسته تنسور (Tensor core) در کارتهای گرافیک NVIDIA چیست؟ + کاربردها و عملکرد
معماری NVIDIA در گذر زمان؛ بررسی نسلهای GPU انویدیا | تاریخچه + ویژگیها
فناوریهای NVLink و NVSwitch
سوکت SXM و نقش کلیدی آن در پردازندههای گرافیکی و سیستمهای پردازشی مدرن
بررسی و معرفی پلتفرم ماژولار NVIDIA HGX
بررسی تخصصی انویدیا DGX

تفاوت RAM و ROM

راهنمای خرید مانیتور HP

کارت گرافیک NVIDIA Quadro NVS 810

راهنمای جامع خرید پردازنده برای گیمرها
- بررسی و معرفی نرم افزار HP ZCentral Remote Boost

- پلتفرم NVIDIA EGX؛ انقلابی در پردازش لبه

- هسته تنسور (Tensor core) در کارتهای گرافیک NVIDIA چیست؟ + کاربردها و عملکرد

- معماری NVIDIA در گذر زمان؛ بررسی نسلهای GPU انویدیا | تاریخچه + ویژگیها

- فناوریهای NVLink و NVSwitch

- سوکت SXM و نقش کلیدی آن در پردازندههای گرافیکی و سیستمهای پردازشی مدرن

- بررسی و معرفی پلتفرم ماژولار NVIDIA HGX

- بررسی تخصصی انویدیا DGX
